网络安全行业以及周边介绍
1.不要用学的技术乱来
2.不要在一切国内平台发表不当言论
3.不要用使用的技术入侵国内任何机构
密码:6k6a
抓包
先安装jre环境,安装完之后验证:cmd->java有东西就完成了
burpsuite
原理
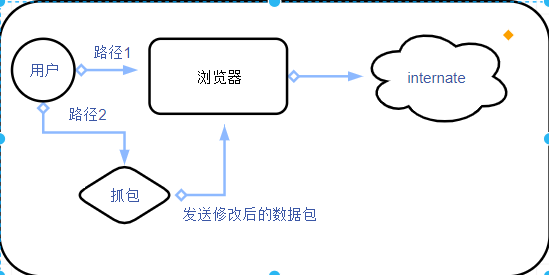
火狐+burp
burpsuite里面->proxy->options
走的时候127.0.0.1:8080
在火狐浏览器里面把代理设置为127.0.0.1:8080
火狐+burp无法浏览https
在浏览器里面输入http://burp/下载证书
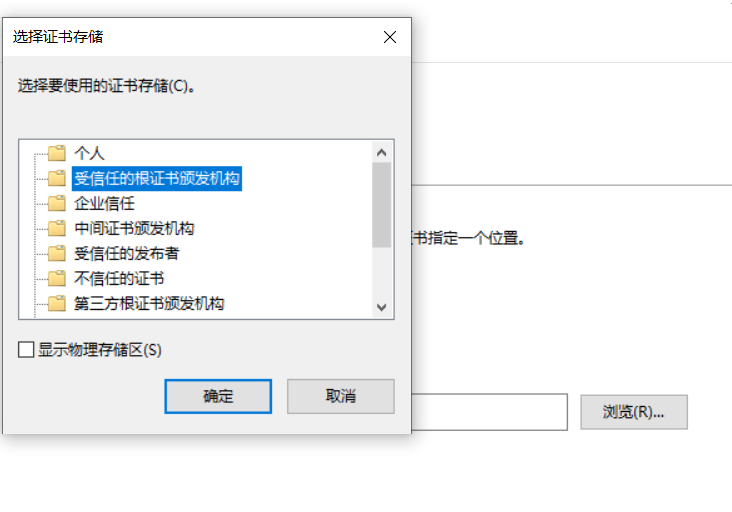
然后在火狐里点击工具->选项->高级->证书->查看证书->导入证书
出现乱码
User options-> Display 更改编码类型
抓取百度数据包
GET /s?ie=utf-8&mod=1&isbd=1&isid=A719837A80D11720&ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=123&fenlei=256&rsv_pq=b804497600000e15&rsv_t=7a36fmMmo8SbLjTA0N%2FEneh0BvCpDToRb20%2B8qKbsxsR8EN%2B4RziZW%2Fj7Vs&rqlang=cn&rsv_enter=0&rsv_dl=ib&rsv_btype=i&rsv_sid=36068_35105_36023_34813_34584_36140_36120_36054_35993_35984_35319_26350_36101_36061&_ss=1&clist=&hsug=&f4s=1&csor=3&_cr1=28503 HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
is_referer: https://www.baidu.com/
is_xhr: 1
X-Requested-With: XMLHttpRequest
Referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=123&fenlei=256&rsv_pq=b804497600000e15&rsv_t=7a36fmMmo8SbLjTA0N%2FEneh0BvCpDToRb20%2B8qKbsxsR8EN%2B4RziZW%2Fj7Vs&rqlang=cn&rsv_enter=0&rsv_dl=ib&rsv_btype=i
Cookie: BAIDUID=A71983DE83BFE41D197C2FDB06A7A80D:FG=1; BIDUPSID=82DEF01D6F2DDF09225229E10038AD8C; PSTM=1642411432; baikeVisitId=d9095499-f022-481b-9dc4-91690fbab182; COOKIE_SESSION=681_4_3_4_8_4_1_0_3_3_0_0_681_142_3_0_1642762023_1635311093_1642762020%7C9%230_4_1635310849%7C1; __sec_t_key=6ea911e1-06f5-47a7-aac6-f8e2d8dea7d8; BD_HOME=1; H_PS_PSSID=36068_35105_36023_34813_34584_36140_36120_36054_35993_35984_35319_26350_36101_36061; BD_UPN=13314352; BA_HECTOR=ag2g0g80a0848g2hej1h3dpvb0q; WWW_ST=1647765487151
DNT: 1
Connection: close
GET 百度地址的提交方式是GET
Host地址名
User-Agent主机信息,包括浏览器类别,浏览主机型号
Accept-Language语言
Referer访问来路,就是表示用户在哪里进行的访问。通过referer可以识别你是来自哪个平台来进行访问的(比如每个直播app的referer值都是不一样的,从而可供商家统计从哪个直播平台引流的人多)
cookie相当于用户登录的信息,用于和浏览器进行对应,从而达到登录状态。被黑客拿到即可被登录用户。
网络传输
一般网络传输的是源代码,信息请求一般以十六进制传输,在网络(网线)里是按01传输的
即:01010101110 ->转化成->hex(十六进制) 》再转化成->人类可读
(前端代码是通过浏览器渲染之后变成我们看到的样子)
burp基本用法
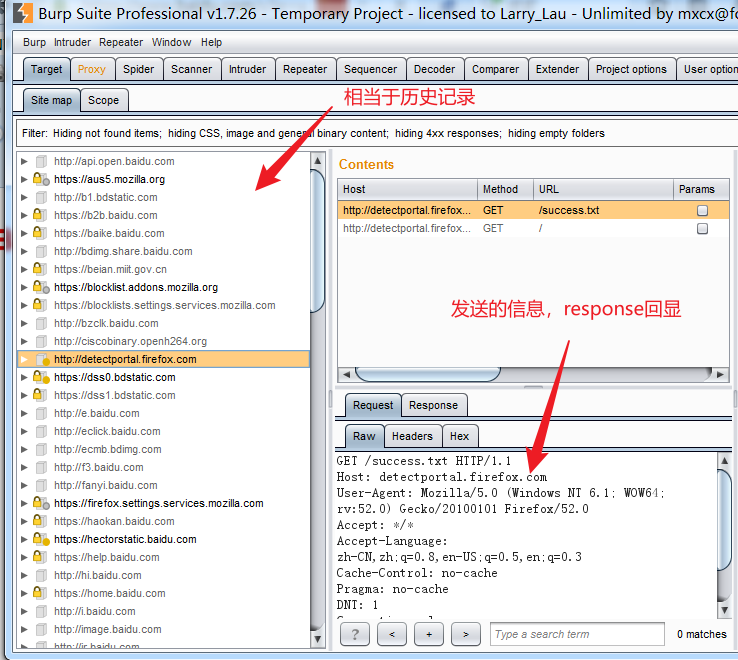
http history
抓包过程中可以看这些数据包分别是按什么顺序提交的,并可以查看相应参数
params判断提交的请求是否有带参数
edited判断是否被修改过
status是http的一个响应:200是正常的,404是没有找到页面
length是该网页大小
MIME type显示类型:html、text(查询时出现的一些联想文本等)、script(特效比如颜色等用js编写的)等
extension后缀名:js、html、php等
options
查看需要通过什么地址才可以让浏览器去使用brupsuite
Spider
爬虫——收集用户信息
可以爬取该网站上的所有信息
Intruder
暴力破解
Repeater
模拟提交
Decoder
转换编码等,快速加密、解密等
comparer
对比两个文本的区别
User options
用户选择的一些默认字体、编码等。
charles使用
分析手机app或者电脑app比较好使
抓包软件——更适合手机抓包,也可用于电脑抓包,但相比于brupsuite它不能把数据包停下来。适合分析手机、电脑app。
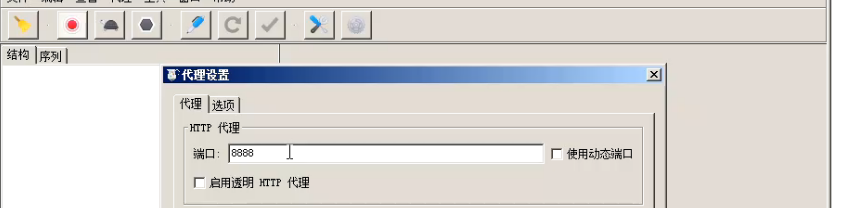
使用8888端口
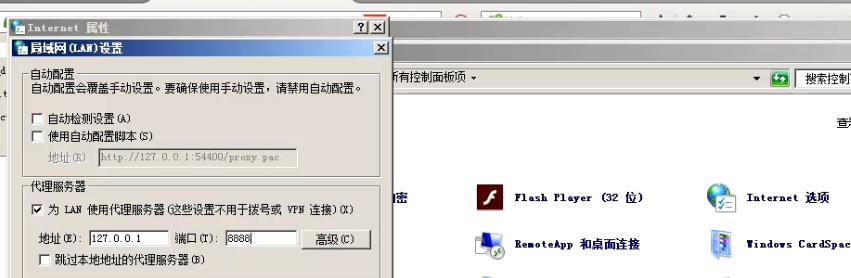
对本地局域网代理服务器改一下。
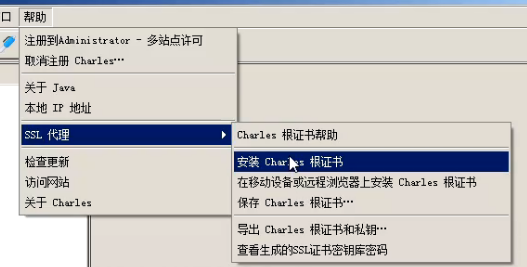
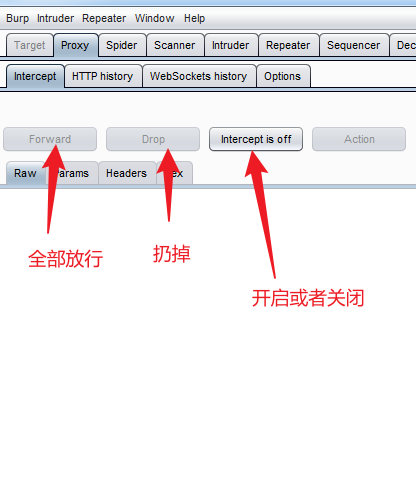
安装后即可进行抓包。但并不能抓到https的数据包。
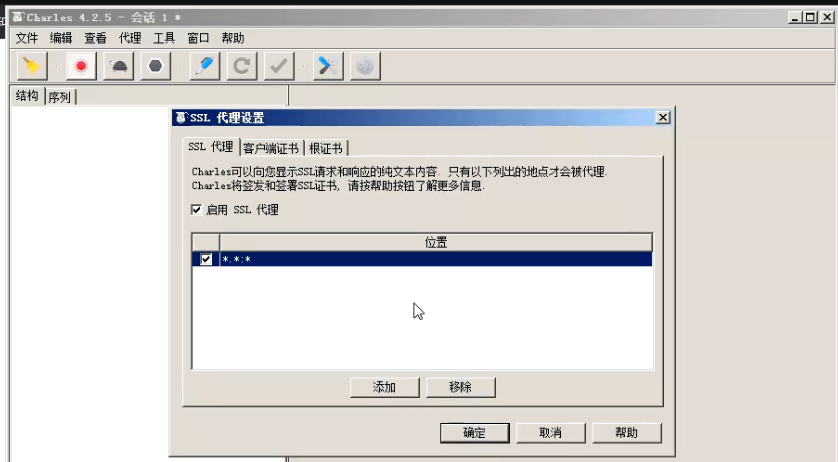
设置为所有的ssl代理都要去抓包
如果需要在远程浏览器或者手机浏览器上安装,需要输入以下地址:

然后浏览上述网页去进行安装。
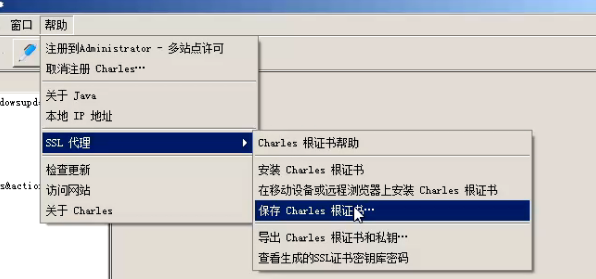
然后就可以抓包https的数据包。
与brupsuite的区别:以树状图呈现抓包数据,功能如下:

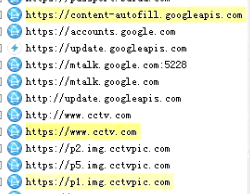
标黄的网址表示正在传输数据的
最适合用于在手机上抓包:
需要把socks代理打开
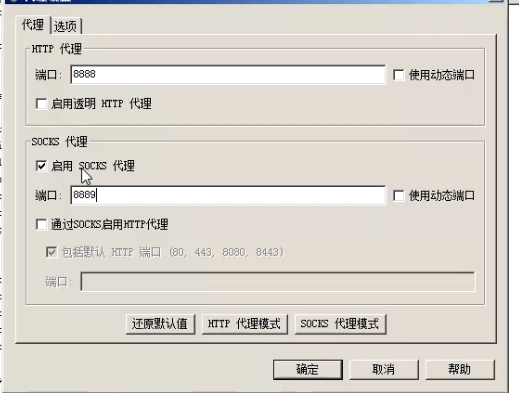
socks代理:拦截socks请求。
web常见术语
刷新:刷新当前页面
跳转:跳到陌生的一个地方
“当用户刷新后,其后台会跳转到一个新的页面”
GET:通过地址栏从服务器拿东西。在GET里刷新和跳转没区别。
POST:提交表单,送给服务器东西。按下回车键,服务器会以GET方式读取一下当前地址,刷新会再次(重复)提交数据到当前页面
刷新:从浏览器取网页的新内容来更新本地缓存,更新的同时保留一些本地变量。
跳转:在地址栏输入新的地址,不会更新本地的缓存和变量。
www:world wide web万维网(由web客户端和服务器组成)
web客户端:浏览器 web browser
浏览器:可以访问网页服务器的web系统,查看html文件(例如IE edge、chrome、Firefox、Opera、Safari)
request:向服务器发送一个请求,服务器会返回一个结果给客户端。
forward:服务器内部发生重定向。(服务器内部自己发生变化,比如小黄网跳转、发送验证码等)
redirect:服务器收到请求后发送一个状态给客户,客户会再次请求,此时url发生了改变。(公司更改网址等)
url:统一资源定位器(比如:http://www.baidu.com/index.php 协议+域名+文件)(https://www.baidu.com/s?ie=utf-8&f=8&rsv bp=1&rsv idx=1&tn=baidu&wd=12306 s=文件 ?=get请求 ie=参数名 utf-8=参数值 &=连接符 )
http:超文本传输协议
https:安全的超文本传输协议
所有的www文件都支持这个标准。http是基于tcp/ip【本身是有漏洞的】传输的。
web服务器(中间件):比如phpstudy的中间件是apache、iis、nginx、tomcat……配合前端和后端的一个协商者
“目标为某个web服务器”:web服务器接收到一个请求,会向客户发送响应消息
需要掌握:
1 http是无连接的!!!限制每一次的连接请求,每一次一个请求,服务器收到请求之后完成应答,断开连接,节省传输时间。
2 http是媒体独立的:只要客户端,服务器都知道这个 数据是干嘛用的,就可以使用http传输。(比如下载东西可以直接用抓包下载)
3 http是无状态的:无状态就是没有记忆能力,如果中途中断了,就需要重传。
http状态码:在brupsuite可以在status栏里看到——
200 成功访问
301 网页被永久转向了其他的url
404 请求的资源不存在
500 服务器内部错误
http数据包解析:
请求头Request:
GET:请求类型
Host:目标
user-agent:用户信息,浏览器是什么等
accept-language:国家
referer:表示从什么地方来的信息
响应头Response类型:
HTTP/1.1 200 OK:协议类型
Content-Type:文档类型
Content-Length:传过来的内容长度(多少个字节)
Expires:什么时候文档过期,不再缓存它
Last-Modified:最后修改时间
refresh:浏览器多长时间后刷新该文档。
server:服务器名字
set-cookie:是否需要cookie支持



